
In dit datablog behandelen we de context van de in eerdere blogs beschreven opbrengsten en geldstromen in het basisonderwijs. De geldstromen en vooral de opbrengsten komen niet zomaar tot stand, maar worden beïnvloed door de (sociale) omgeving van de basisschool.
Waarom is de omgeving belangrijk?
Zoals we in onze blog over de prestaties van scholen al schreven, worden in de wetenschap en het onderwijs vaak gewerkt met gecorrigeerde prestaties of opbrengsten in plaats van de ‘ruwe’ scores van scholen te gebruiken. Dat heeft er mee te maken dat de prestaties van scholen niet alleen toe te schrijven zijn aan de kwaliteit van de school, maar ook worden beïnvloed door de omgeving. Voorbeelden zijn scholen in ‘rijke’ buurten waar relatief veel kinderen met een onderwijsvoorsprong in- en uitstromen. Deze scholen scoren over het algemeen hogere ruwe scores dan scholen in ‘armere’ wijken.
Omgevingsfactoren
Welke omgevingsfactoren zijn dan belangrijk als context voor de opbrengsten voor scholen? Over het algemeen worden de volgende variabelen gebruikt om opbrengsten te corrigeren:
- Het opleidingsniveau van de ouders
- Het inkomen per gezin
- Sociaaleconomische status
- De koppeling tussen voedingsgebieden van scholen op postcode niveau (4 cijfers) en de school zelf
- Herkomst van ouders
- Overige data uit wijken en buurten van het Centraal Bureau voor de Statistiek
Deze variabelen worden in de wetenschap veel gebruikt om de opbrengsten van scholen te meten. Een voorbeeld van zo’n correctiemodel werd veel gebruikt door professor Dronkers van de Universiteit van Maastricht. Hij plaatste de opbrengsten van scholen in perspectief van de zogenaamde leefbarometer (een website waarin de leefbaarheid per buurt wordt weergegeven aan de hand van 100 indicatoren).
Context geldstromen en opbrengsten
Veel gegevens die hierboven zijn opgesomd zijn te vinden op de website van het CBS. In een eerdere blog werd beschreven hoe die data kunnen worden gevonden en gebruikt. Om de relatie tussen geldstromen en opbrengsten in context te kunnen plaatsen is het belangrijk dat jullie ook van die uitleg en data gebruik maken. Een belangrijke koppelvariabele tussen contextinformatie en gegevens over geldstromen of opbrengsten is de postcode. In de wijken en buurten van het CBS zijn postcodegegevens opgenomen. Verder is voor basisscholen een dataset beschikbaar waarin per postcode terug te vinden is naar welke school de leerlingen gaan.
Voedingsgebied per school
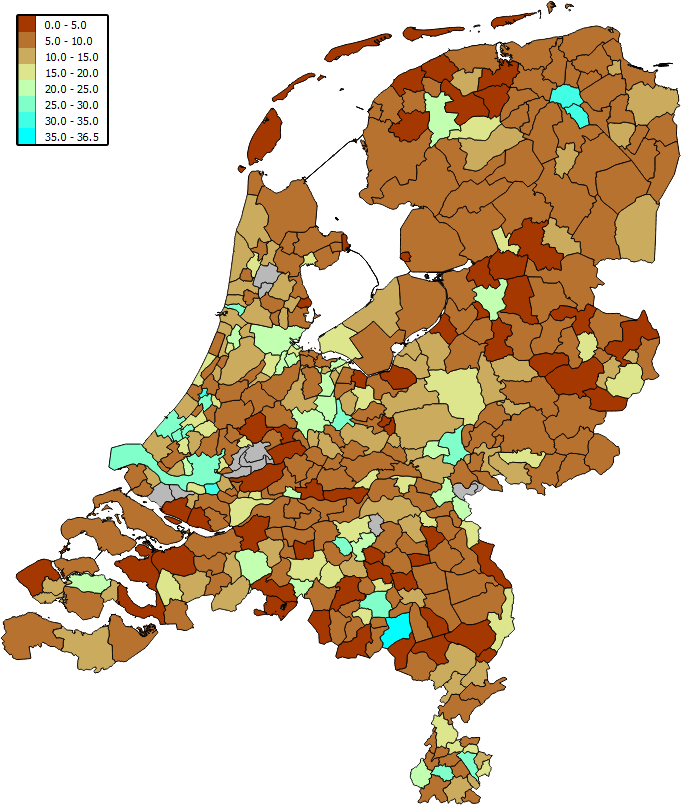
Op basis van deze laatstgenoemde dataset hebben we een eenvoudige visualisatie gemaakt van hoe tussen scholen verschillen kunnen zijn in de grootte van het gebied waar de leerlingen vandaan komen. Op basis van de het totaal overzicht is het mogelijk om per school (BRIN code én vestigingsnummer is samen een unieke code per school) het aantal ‘bediende’ postcodegebieden na te gaan.
Gemiddeld blijkt dat iets meer dan 13 te zijn, met een uitschieter van 270 postcodegebieden voor de Berkenschutse, een school die bijzonder gespecialiseerd is in o.a. onderwijs voor leerlingen met epilepsie of autisme. Om dit te visualiseren in onderstaande kaart hebben we het geaggregeerd op gemeenteniveau. Hier is de gemeente Heeze-Leende met 36,5 de uitschieter, wat veroorzaakt wordt door de Berkenschutse, één van de acht scholen binnen de gemeentegrenzen, die het gemiddelde van de andere scholen – 3,14 – voor deze gemeente naar 36,5 haalt.
Naast de wijken en buurten van het CBS maakt het CBS ook ‘maatwerk’-overzichten waarvan er twee eveneens relevant zijn:
- Informatie over huishoudens, leeftijden, geslacht en herkomst naar pc4 over 2015 kun je hier vinden
- Informatie over inkomen naar PC4 over 2013 kun je hier vinden
Doe je mee?
Op 9 september 2016, aan de vooravond van Prinsjesdag vindt Accountability Hack plaats. Tijdens deze hackathon gaan we met open data geldstromen en prestaties van de overheid in kaart brengen. Doe je mee? Aanmelden kan hier.